
 Honesty
Honesty 

 Typecho
Typecho 前言:什么是大数据?先说什么不是
作为互联网从业者,"大数据"这个词你肯定听得耳朵都起茧了。面试官问、领导讲、产品经理吹、销售拿来忽悠客户...
但是,到底什么是大数据?
在回答这个问题之前,让我先说说什么不是大数据:
(海量图片/日志/记录)"] B["某个具体技术
(Hadoop≠大数据)"] C["处理速度快
(运营商处理数据也很快)"] end subgraph IS["✅ 大数据真正的含义"] D["处理大量数据的
技术方法合集"] E["通过数据分析
发掘数据价值"] F["一整套技术栈
而非单一工具"] end NOT -->|"本质区别"| IS style NOT fill:#FFB6C1 style IS fill:#90EE90
简单说:
- 不是数据多就叫大数据:你电脑里存了10TB的小电影,那叫硬盘快满了,不叫大数据
- 不是用了Hadoop就叫大数据:就像用了菜刀不代表你是厨师
- 不是处理快就叫大数据:银行核心系统处理交易飞快,但那是OLTP,不是大数据
大数据的核心价值在于:通过数据分析,从海量数据中发掘出业务价值。
技术只是手段,洞察才是目的。
一、大数据发展简史:一部"造轮子"的历史
让我们坐上时光机,看看大数据是怎么一步步发展起来的:
1.1 Google三驾马车(2003-2004)
一切的起源,都要从Google的三篇论文说起:
| 论文 | 开源实现 | 解决什么问题 |
|---|---|---|
| GFS (Google File System) | HDFS | 海量数据怎么存 |
| MapReduce | Hadoop MapReduce | 海量数据怎么算 |
| BigTable | HBase | 海量数据怎么查 |
这三篇论文直接奠定了大数据的技术基础。Google自己用的是闭源版本,但论文思想被Apache社区实现成了开源版本,这才有了后来繁荣的大数据生态。
🤔 冷知识:Google内部早就不用MapReduce了,但整个行业还在用它的开源实现...科技圈的"知识诅咒"。
1.2 Hadoop时代(2006-2012)
Hadoop一出,各大公司趋之若鹜。那个年代的标配是:
遇到数据问题 → 上Hadoop!
Hadoop太慢 → 加机器!
还是慢 → 再加机器!虽然简单粗暴,但确实管用。
1.3 Spark时代(2012-2016)
Spark出现后,大家终于不用忍受MapReduce的龟速了。"比Hadoop快100倍"的宣传语响彻云霄(虽然实际上没那么夸张)。
这个时期最流行的是Lambda架构:批处理和流处理并行,用批处理保证准确性,用流处理保证时效性。
1.4 Flink与实时时代(2016至今)
Flink的出现让"真正的流处理"成为可能。不再是Spark Streaming那种"微批处理伪装成流处理",而是真正的事件驱动、低延迟处理。
现在,Kappa架构(只用流处理)开始流行,数据湖技术(Iceberg/Hudi/Delta Lake)也在重塑整个生态。
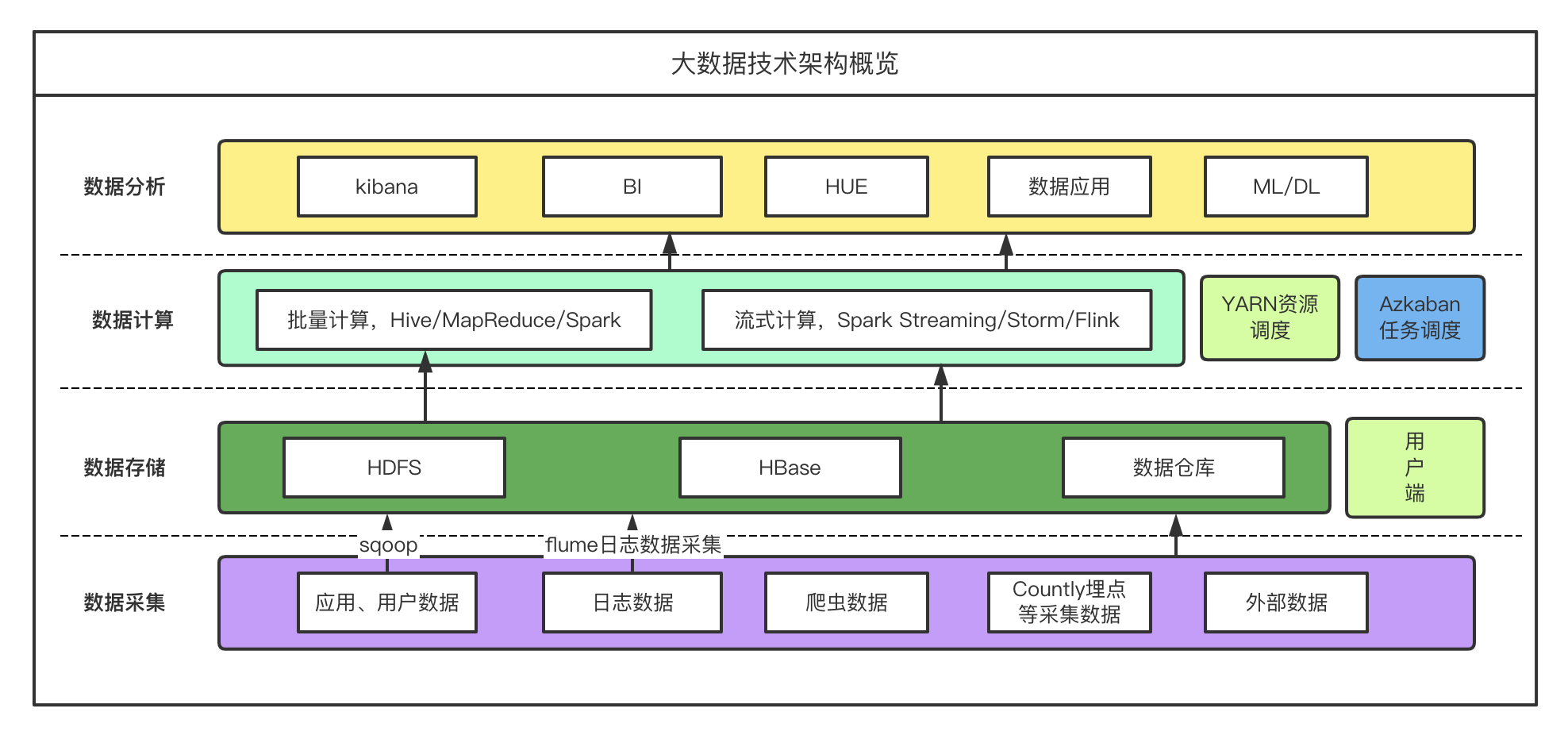
二、大数据技术架构全景图
先来一张全景图,让你对整个技术栈有个直观认识:
MySQL/Oracle"] S2["日志数据
Nginx/App Log"] S3["消息队列
Kafka"] S4["外部数据
API/爬虫"] end subgraph COLLECT["🚚 数据采集层"] C1["Sqoop
数据库同步"] C2["Flume/Filebeat
日志采集"] C3["Kafka Connect
流式接入"] C4["DataX
异构数据同步"] end subgraph STORE["💾 数据存储层"] ST1["HDFS
分布式文件系统"] ST2["HBase
列式数据库"] ST3["Kafka
消息存储"] ST4["数据湖
Iceberg/Hudi"] end subgraph COMPUTE["⚡ 数据计算层"] CP1["Hive/SparkSQL
批处理"] CP2["Spark
内存计算"] CP3["Flink
流处理"] CP4["Presto/Trino
即席查询"] end subgraph SCHEDULE["🎯 资源调度层"] SC1["YARN"] SC2["Kubernetes"] SC3["Mesos"] end subgraph APP["📊 数据应用层"] A1["数据仓库
OLAP分析"] A2["实时大屏
监控告警"] A3["机器学习
推荐/风控"] A4["数据服务
API输出"] end subgraph TOOL["🔧 辅助工具"] T1["Azkaban/Airflow
任务调度"] T2["Zookeeper
协调服务"] T3["Atlas/Datahub
元数据管理"] end SOURCE --> COLLECT COLLECT --> STORE STORE --> COMPUTE COMPUTE --> APP SCHEDULE -.->|"资源管理"| COMPUTE TOOL -.->|"任务编排"| COMPUTE
看着复杂?别怕,让我一层一层给你拆解。
三、核心组件详解
3.1 Hadoop:大数据的地基
Hadoop是大数据的"老祖宗",虽然现在很多计算场景被Spark/Flink取代,但HDFS依然是存储层的绝对霸主。
元数据管理
知道数据在哪"] DN1["DataNode 1"] DN2["DataNode 2"] DN3["DataNode 3"] NN --> DN1 & DN2 & DN3 end subgraph MR["MapReduce - 分布式计算"] MAP["Map阶段
打散数据"] SHUFFLE["Shuffle
数据重分布"] REDUCE["Reduce阶段
聚合结果"] MAP --> SHUFFLE --> REDUCE end subgraph YARN["YARN - 资源调度"] RM["ResourceManager
老大,管资源"] NM1["NodeManager 1
小弟,干活"] NM2["NodeManager 2"] NM3["NodeManager 3"] RM --> NM1 & NM2 & NM3 end end
HDFS核心设计思想:
| 特性 | 说明 | 为什么这么设计 |
|---|---|---|
| 分块存储 | 文件切成128MB块 | 便于分布式存储和并行处理 |
| 多副本 | 默认3副本 | 容错,任何节点挂了数据不丢 |
| 一次写入多次读取 | 不支持修改 | 简化一致性问题 |
| 移动计算而非数据 | 计算靠近数据 | 减少网络传输 |
MapReduce的直觉理解:
假设你要统计一本1000页的书里每个单词出现多少次:
传统方式:一个人从头看到尾,边看边记录(太慢)
MapReduce方式:
1. Map:把书撕成100份,分给100个人,每人数自己那10页的单词
2. Shuffle:把相同单词的统计结果收集到一起
3. Reduce:把每个单词的分散统计结果加起来这就是"分而治之"的精髓。
3.2 Hive:让SQL飞入大数据
Hive的出现解决了一个痛点:不是每个分析师都会写MapReduce代码。
WHERE date='2024-01-01'"] HIVE["Hive
SQL解析器"] MR["MapReduce任务
或 Spark任务"] HDFS["HDFS
底层存储"] SQL --> HIVE HIVE -->|"翻译成"| MR MR -->|"读写"| HDFS
Hive的本质:一个SQL到MapReduce/Spark的翻译器,外加一套元数据管理系统。
Hive的优缺点:
| 优点 | 缺点 |
|---|---|
| 会SQL就能分析大数据 | 延迟高,不适合实时查询 |
| 成熟稳定,生态丰富 | 小文件问题 |
| 支持UDF扩展 | 调优门槛高 |
Hive表类型:
-- 内部表:Hive全权管理,删表数据也删
CREATE TABLE internal_table (
id BIGINT,
name STRING
) STORED AS ORC;
-- 外部表:Hive只管元数据,删表数据还在
CREATE EXTERNAL TABLE external_table (
id BIGINT,
name STRING
)
LOCATION '/data/external/';
-- 分区表:按某个字段物理分目录,查询快得飞起
CREATE TABLE partitioned_table (
id BIGINT,
name STRING
)
PARTITIONED BY (dt STRING)
STORED AS PARQUET;💡 最佳实践:生产环境用外部表 + 分区 + 列式存储(ORC/Parquet),查询性能提升10倍不是梦。
3.3 Spark:内存计算的王者
如果说Hadoop是大数据的"蒸汽机",那Spark就是"内燃机"——同样是跑,但快多了。
RDD分布式计算引擎"] SQL["Spark SQL
结构化数据处理"] STREAMING["Spark Streaming
微批流处理"] MLLIB["MLlib
机器学习库"] GRAPHX["GraphX
图计算"] SQL & STREAMING & MLLIB & GRAPHX --> CORE CORE --> DEPLOY["部署模式"] subgraph DEPLOY D1["YARN"] D2["K8s"] D3["Standalone"] D4["Local"] end end
Spark为什么快?
简单说:MapReduce每一步都要写磁盘,Spark尽量在内存里完成,最后才落盘。
RDD:Spark的核心抽象
RDD(Resilient Distributed Dataset)是Spark的灵魂:
# 一个简单的WordCount
from pyspark import SparkContext
sc = SparkContext("local", "WordCount")
# 这就是RDD的链式操作
word_counts = (
sc.textFile("hdfs://path/to/file") # 读取文件,创建RDD
.flatMap(lambda line: line.split()) # 切分单词
.map(lambda word: (word, 1)) # 映射成(word, 1)
.reduceByKey(lambda a, b: a + b) # 按key聚合
)
word_counts.saveAsTextFile("hdfs://path/to/output")Spark SQL示例:
from pyspark.sql import SparkSession
spark = SparkSession.builder.appName("Example").getOrCreate()
# 读取数据
df = spark.read.parquet("hdfs://path/to/data")
# 就像写SQL一样
result = df.filter(df.age > 18) \
.groupBy("city") \
.agg({"salary": "avg", "age": "max"}) \
.orderBy("avg(salary)", ascending=False)
# 或者直接写SQL
df.createOrReplaceTempView("people")
result = spark.sql("""
SELECT city, AVG(salary) as avg_salary
FROM people
WHERE age > 18
GROUP BY city
ORDER BY avg_salary DESC
""")3.4 Flink:真正的流处理之王
Spark Streaming说自己是流处理,其实是微批处理(把流切成小批次处理)。而Flink是真正的流处理——来一条处理一条。
1秒"] --> P1["处理"] I1 --> B2["批次2
1秒"] --> P2["处理"] I1 --> B3["批次3
1秒"] --> P3["处理"] end subgraph TRUE["Flink - 真流处理"] I2["数据流"] --> E1["事件1"] --> PP["处理"] I2 --> E2["事件2"] --> PP I2 --> E3["事件3"] --> PP end MICRO -->|"延迟:秒级"| R1["结果"] TRUE -->|"延迟:毫秒级"| R2["结果"] style MICRO fill:#FFE4B5 style TRUE fill:#90EE90
Flink的核心能力:
| 能力 | 说明 |
|---|---|
| 精确一次语义 | Exactly-Once,数据不丢不重 |
| 事件时间处理 | 按数据产生时间而非到达时间处理 |
| 状态管理 | 内置状态后端,支持超大状态 |
| 窗口计算 | 灵活的窗口类型(滚动、滑动、会话) |
| 高吞吐低延迟 | 毫秒级延迟,百万级TPS |
Flink代码示例:
// 实时统计每5秒内各城市的订单金额
DataStream<Order> orders = env.addSource(new KafkaSource<>());
orders
.keyBy(order -> order.getCity())
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(new SumAggregate())
.addSink(new ElasticsearchSink<>());什么时候用Spark,什么时候用Flink?
延迟要求<1秒?"} Q1 -->|"是"| FLINK["Flink ✅"] Q1 -->|"否"| Q2{"数据量级?"} Q2 -->|"TB级批处理"| SPARK["Spark ✅"] Q2 -->|"PB级批处理"| Q3{"对SQL友好度要求?"} Q3 -->|"高"| HIVE["Hive on Spark/Tez ✅"] Q3 -->|"一般"| SPARK style FLINK fill:#90EE90 style SPARK fill:#87CEEB style HIVE fill:#DDA0DD
3.5 HBase:海量数据秒级查询
当你需要在数十亿行数据中毫秒级查询某一行时,HBase就是你的答案。
协调服务"] ZK --> MASTER["HMaster
管理RegionServer"] MASTER --> RS1["RegionServer 1"] MASTER --> RS2["RegionServer 2"] MASTER --> RS3["RegionServer 3"] RS1 --> HDFS["HDFS
底层存储"] RS2 --> HDFS RS3 --> HDFS end subgraph REGION["Region内部"] MEM["MemStore
内存写缓存"] WAL["WAL
预写日志"] HFILE["HFile
磁盘存储"] MEM -->|"flush"| HFILE WAL -->|"持久化"| HDFS end
HBase的数据模型:
Column Family: info Column Family: stats
┌─────────────────────────┬─────────────────────────┐
│ name │ age │ visits │ score │
┌───────────────────┼──────────┼──────────────┼───────────┼────────────┤
│ RowKey: user_001 │ 张三 │ 25 │ 100 │ 95.5 │
├───────────────────┼──────────┼──────────────┼───────────┼────────────┤
│ RowKey: user_002 │ 李四 │ 30 │ 200 │ 88.0 │
└───────────────────┴──────────┴──────────────┴───────────┴────────────┘
特点:
- RowKey是唯一索引,设计好RowKey是关键
- 列可以动态添加,不需要预定义
- 每个Cell可以有多个版本(时间戳)HBase适用场景:
| 场景 | 示例 |
|---|---|
| 用户画像 | 根据用户ID快速查询用户标签 |
| 时序数据 | 监控数据、IoT传感器数据 |
| 订单详情 | 根据订单号查询订单信息 |
| 消息存储 | IM消息历史记录 |
3.6 Kafka:数据管道的标准
Kafka是大数据生态中的"高速公路",几乎所有实时数据都要经过它。
实时计算"] C2["Spark
批处理"] C3["ES
搜索索引"] end P1 & P2 & P3 --> KAFKA KAFKA --> C1 & C2 & C3
Kafka核心概念:
| 概念 | 说明 |
|---|---|
| Topic | 消息的分类,类似于表 |
| Partition | Topic的分区,并行度的关键 |
| Offset | 消息在Partition中的位置 |
| Consumer Group | 消费者组,组内消费者分摊消息 |
| Replica | 副本,保证高可用 |
Kafka为什么这么快?
比随机写快1000倍"] F2["Page Cache
利用操作系统缓存"] F3["零拷贝
sendfile系统调用"] F4["批量处理
攒一批再发"] F5["分区并行
水平扩展"] end
3.7 数据采集:Sqoop与DataX
数据要先进来,才能分析。数据采集工具负责把数据从各种源搬到大数据平台。
Hadoop官方"] DATAX["DataX
阿里开源"] CDC["Debezium
CDC实时同步"] end subgraph TARGET["目标"] HDFS["HDFS"] HIVE["Hive"] KAFKA["Kafka"] end SOURCE --> ETL --> TARGET
Sqoop vs DataX:
| 对比项 | Sqoop | DataX |
|---|---|---|
| 并行方式 | MapReduce | 多线程 |
| 支持数据源 | 主要是关系型数据库 | 几乎所有数据源 |
| 增量同步 | 支持 | 支持 |
| 资源消耗 | 需要YARN资源 | 单机即可 |
| 适用场景 | 大批量数据同步 | 灵活的ETL场景 |
DataX示例配置:
{
"job": {
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"connection": [{
"jdbcUrl": ["jdbc:mysql://localhost:3306/test"],
"table": ["user"]
}],
"username": "root",
"password": "password",
"column": ["id", "name", "age"]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"path": "/data/user",
"fileType": "orc",
"column": [
{"name": "id", "type": "bigint"},
{"name": "name", "type": "string"},
{"name": "age", "type": "int"}
]
}
}
}]
}
}3.8 任务调度:Azkaban与Airflow
大数据任务往往有复杂的依赖关系,任务调度器负责按正确的顺序执行它们。
00:00"] --> T2["数据清洗
01:00"] T2 --> T3["维度表更新
02:00"] T2 --> T4["事实表计算
02:00"] T3 & T4 --> T5["数据聚合
03:00"] T5 --> T6["报表生成
04:00"] T5 --> T7["数据导出
04:00"] end
Azkaban vs Airflow:
| 对比项 | Azkaban | Airflow |
|---|---|---|
| 开发语言 | Java | Python |
| DAG定义 | 配置文件 | Python代码 |
| 学习曲线 | 低 | 中等 |
| 灵活性 | 一般 | 非常灵活 |
| 社区活跃度 | 一般 | 非常活跃 |
| 适用场景 | 简单的定时任务 | 复杂的数据管道 |
Airflow DAG示例:
from airflow import DAG
from airflow.operators.bash import BashOperator
from datetime import datetime, timedelta
default_args = {
'owner': 'data-team',
'retries': 3,
'retry_delay': timedelta(minutes=5),
}
with DAG(
'daily_etl',
default_args=default_args,
schedule_interval='0 0 * * *', # 每天0点
start_date=datetime(2024, 1, 1),
) as dag:
extract = BashOperator(
task_id='extract',
bash_command='python extract.py'
)
transform = BashOperator(
task_id='transform',
bash_command='spark-submit transform.py'
)
load = BashOperator(
task_id='load',
bash_command='python load.py'
)
extract >> transform >> load3.9 即席查询:Presto/Trino与Impala
当分析师需要交互式地探索数据时,Hive的分钟级延迟就太慢了。
Presto/Trino的杀手锏:
- 联邦查询:一条SQL可以同时查Hive、MySQL、ES等多个数据源
- 内存计算:中间结果不落盘
- MPP架构:大规模并行处理
-- Presto联邦查询示例
SELECT
h.user_id,
h.order_amount,
m.user_name,
e.last_login
FROM hive.dw.orders h
JOIN mysql.crm.users m ON h.user_id = m.id
JOIN elasticsearch.logs.user_activity e ON h.user_id = e.user_id
WHERE h.order_date = '2024-01-01'四、现代大数据架构演进
4.1 从Lambda到Kappa
Hive/Spark"] SOURCE1 --> SPEED["速度层
Storm/Spark Streaming"] BATCH --> SERVE1["服务层"] SPEED --> SERVE1 SERVE1 --> APP1["应用"] end subgraph KAPPA["Kappa架构"] SOURCE2["数据源"] --> STREAM["流处理层
Flink"] STREAM --> SERVE2["服务层"] SERVE2 --> APP2["应用"] end LAMBDA -->|"演进"| KAPPA
| 架构 | 优点 | 缺点 |
|---|---|---|
| Lambda | 批处理保证准确性 | 维护两套代码,复杂度高 |
| Kappa | 一套代码,架构简单 | 对流处理引擎要求高 |
4.2 数据湖与湖仓一体
传统数据仓库的问题:数据进去容易,改起来难。
数据湖的理念:先把数据存进来,Schema后定义。
写入时定义结构"] W2 --> W3["结构化存储"] end subgraph LAKE["数据湖"] L1["原始数据直接存入"] --> L2["Schema on Read
读取时定义结构"] L2 --> L3["支持各种格式"] end subgraph LAKEHOUSE["湖仓一体"] LH1["数据湖的灵活性"] LH2["数仓的ACID事务"] LH3["统一的元数据"] LH1 & LH2 & LH3 --> LH4["Iceberg / Hudi / Delta Lake"] end WAREHOUSE & LAKE -->|"融合"| LAKEHOUSE
三大湖仓格式对比:
| 特性 | Apache Iceberg | Apache Hudi | Delta Lake |
|---|---|---|---|
| 开源方 | Netflix | Uber | Databricks |
| ACID事务 | ✅ | ✅ | ✅ |
| Time Travel | ✅ | ✅ | ✅ |
| 增量查询 | ✅ | ✅ | ✅ |
| 计算引擎支持 | Spark/Flink/Trino | Spark/Flink | 主要是Spark |
| 社区活跃度 | 🔥🔥🔥 | 🔥🔥 | 🔥🔥 |
五、技术选型指南
5.1 选型决策树
5.2 常见架构组合
组合一:经典批处理架构
数据源 → Sqoop/DataX → HDFS → Hive → 报表/BI适用于:离线分析、T+1报表
组合二:Lambda架构
数据源 → Kafka → Flink(实时) + Spark(批量) → 服务层适用于:需要兼顾实时和准确性的场景
组合三:实时数仓架构
数据源 → Kafka → Flink → Kafka(结果) → ClickHouse/ES → 应用适用于:实时大屏、实时风控
组合四:湖仓一体架构
数据源 → Kafka → Flink → Iceberg(数据湖) → Trino(查询) → 应用适用于:既要灵活又要性能的现代数据平台
六、总结
大数据技术发展到今天,已经不是某个单一技术能代表的了,而是一整个生态系统:
💡 最后的忠告:
- 不要为了用技术而用技术——先搞清楚业务需求
- 不要一上来就追求最新最潮——稳定的老技术可能更适合你
- 单纯掌握技术不够——最重要的是通过数据创造业务价值
技术是手段,洞察是目的,价值是结果。
参考资料
官方文档
推荐书籍
- 《Hadoop权威指南》- 大数据入门必读
- 《Spark快速大数据分析》- Spark实战指南
- 《Flink原理与实践》- 流处理深入理解
学习资源
{kind=link}
🎉 大数据技术浩如烟海,但核心就那么几个。掌握了本文的内容,你就有了一张完整的地图。
剩下的,就是在实践中不断深入每个技术点。
Happy Big Data! 🚀